
2022-10-27 376

生活中,你我一定都看到过这种「xx元爆改出租屋」,「爆改小汽车」之类的文章,做为IT人,折腾的劲头一点也不差。
软件开发过程中,你是否有时候,会拿着业务提供的一个个CSV或者JSON的数据文件,写个解析程序,把它们存到数据库里,再在自己的程序里通过数据库读出来?
其实不用这么麻烦,还绕了一个大圈。
今天,我们一起来「爆改」JSON/CSV这类文件,把它们打造成 MySQL一样的关系型数据库,一套SQL查询走天下。:-)
第一步:代码里加入Maven依赖
<dependency> <groupId>org.apache.calcite</groupId> <artifactId>calcite-file</artifactId> <version>1.21.0</version> </dependency>
通过这一步,你大概就看出来,咱们今天的爆改,主要依赖 Calcite,这个Apache的顶级项目。
来张官网截图感受下:
简单介绍的话,它是个数据库查询和优化的引擎,不负责具体的存储。
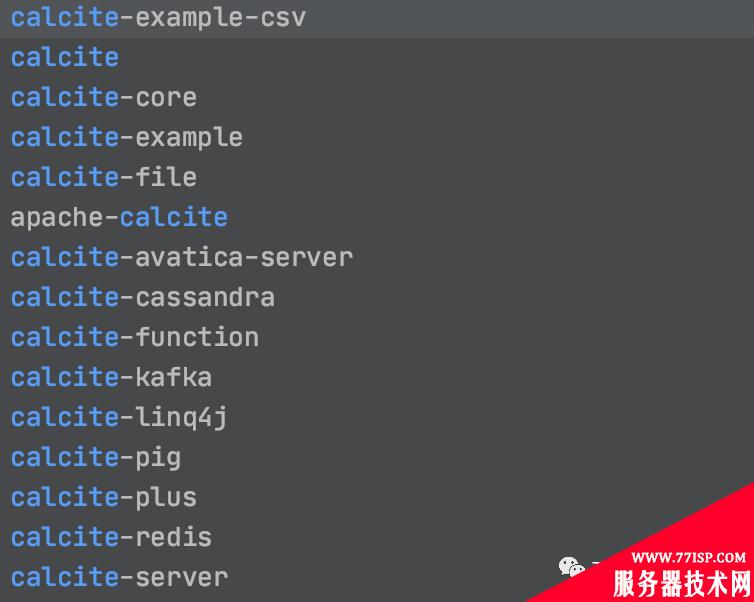
所以介绍里人家自己也说了,是你高性能数据库的地基。许多的开源项目是基于它做的,比如大名鼎鼎的这些:

第二步:添加配置文件
配置的JSON 文件,一般是下面这样子:
改造的配置文件,就像行军打仗的地图一样,来告诉我们往哪走,这里的配置文件,对应到关系型数据库里,就像是哪个库,哪些表一样。
{
"version":"1.0",
"defaultSchema":"SALES",
"schemas":[
{
"name":"SALES",
"type":"custom",
"factory":"org.apache.calcite.adapter.file.FileSchemaFactory",
"operand":{
"directory":"sales"
}
}
]
}
其中schemas 表示都有哪些数据库, defaultSchema 当然是默认数据库了。factory 表示当前的数据文件,我们使用哪种Schema的形式进行解析。因为 Calcite 可以支持多种数据格式,通过这个图你也能感受到几分吧。
第三步:JDBC Style
通过 JDBC 的形式就能连接到我们自己的数据库查询了。代码和一般的JDBC类似,区别只在于连接URL的写法上,需要将配置文件的位置声明一下。
publicclassDemo{
publicstaticvoidmain(String[]args)throwsSQLException,ClassNotFoundException{
Class.forName("org.apache.calcite.jdbc.Driver");
Propertiesconfig=newProperties();
config.put("model","./src/main/resources/model.json");
Stringsql="select*fromhello";
try(Connectioncon=DriverManager.getConnection("jdbc:calcite:",config)){
try(Statementstmt=con.createStatement()){
ResultSetrs=stmt.executeQuery(sql);
while(rs.next()){
System.out.println(rs.getString(2));
}
}
}
}
}
其中SQL 语句,可以支持条件过滤,join 等所有的标准SQL。
整体项目结构如下:

PS: 忘了提一句,对于CSV文件,第一行需要将各列列名和类型加上,表示数据库表里定义的列。

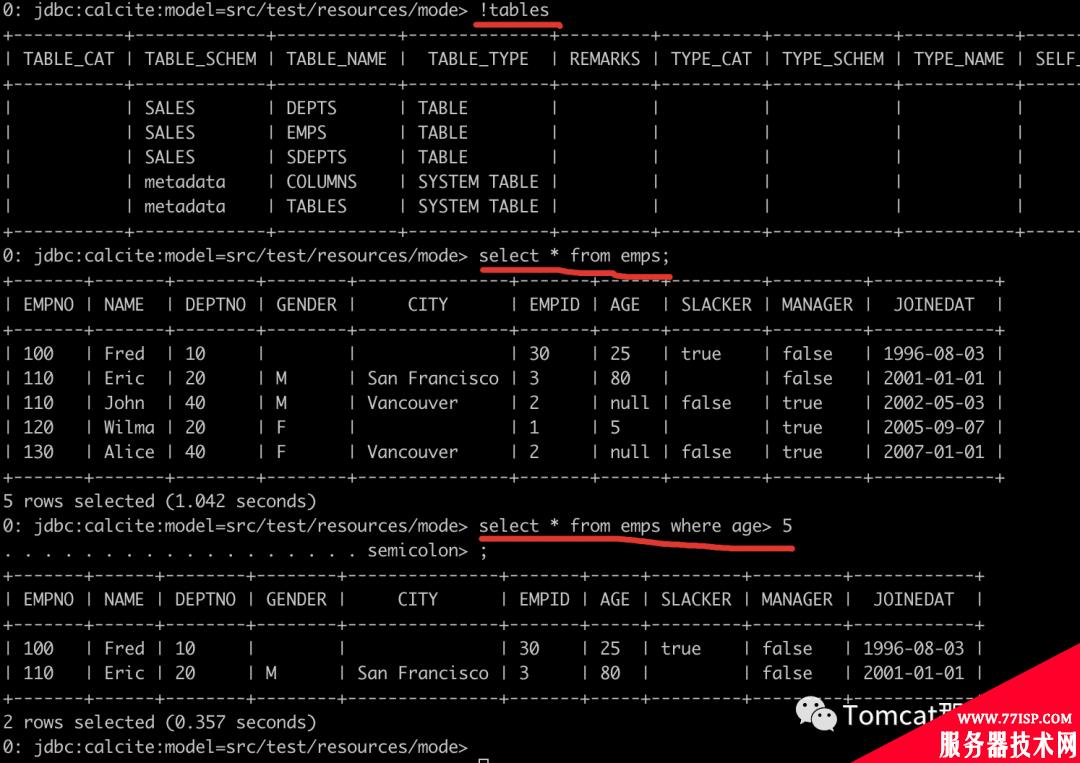
你说我很忙,不想啰哩啰嗦再写个Java程序,办法也还有。有个程序叫 sqlline,可以方便你在命令行里执行,一个脚本连接到对应的文件数据库之后,就开始你飞一般的SQL表演吧。
sqlline>!connectjdbc:calcite:model=src/main/resources/model.jsonadminadmin
原文链接:https://77isp.com/post/10257.html
=========================================
https://77isp.com/ 为 “云服务器技术网” 唯一官方服务平台,请勿相信其他任何渠道。
数据库技术 2022-03-28
网站技术 2022-11-26
网站技术 2023-01-07
网站技术 2022-11-17
Windows相关 2022-02-23
网站技术 2023-01-14
Windows相关 2022-02-16
Windows相关 2022-02-16
Linux相关 2022-02-27
数据库技术 2022-02-20
抠敌 2023年10月23日
嚼餐 2023年10月23日
男忌 2023年10月22日
瓮仆 2023年10月22日
簿偌 2023年10月22日
扫码二维码
获取最新动态
