
2022-10-27 370

前言
在新的公司经常会遇到上百行的 SQL 代码,主要用于进行数据获取与处理,因为公司使用阿里的 ADB,所以希望将数据间简单处理的逻辑都放在 ADB 上进行。这让我适应了一段时间,毕竟之前的经验都是尽量将 SQL 简单化,然后通过代码对获取的数据进行处理,所以我 SQL 功力不强。
SQL 不强,那就学一下,所以在学习的过程中,突然好奇,我是否可以通过 MySQL 来解算法题,这个过程遇到了很多坑,但探究的过程还是很有趣的。
大部分 SQL 语言细节或其他知识,都会在最后的参考小节中给出对应的文章,这些文章是我学习 SQL 语法和解决具体问题的内容。
八皇后
国际象棋中的皇后可以横向、纵向、斜向移动,所谓八皇后问题就是如何在一个 8×8 的棋盘上放置 8 个皇后,使得任意 2 个皇后都不在同一条横线、竖线、斜线方向上,具体如下图所示,图中在棋盘的 (1,1) 位置放置一个皇后,那么图中绿色的部分就不能放置其他皇后。
问题是:8 个皇后在 8×8 的棋盘上可以有多少种放法?

这是一道经典的回溯算法题,回溯算法的本质其实就是通过递归的方式遍历完所有的情况,最终获得所有的情况。
回溯算法的关键如其名,就是做回溯操作,比如某个皇后,尝试了一行中的 8 个格子,都无法满足条件,这就说明此前皇后的放置位置有问题,我们需要回到此前的某次操作并修改那次操作,比如将那次操作的皇后放置到新的位置。
回溯算法很适合用递归的方式去实现,递归的本质是函数帧的出栈与入栈,即栈的出入操作满足回溯的特点。
SQL 的差异
聪明的你在遇到如果通过 MySQL 实现八皇后问题时,肯定会 Google 搜索一下前人的解决方法,遗憾的是,我没有搜索到参考答案,唯一搜索的与 SQL 相关的答案是用 PL/SQL 实现的。
SQL 其实就是一种邻域内语言 (DDL),它有自己的标准,但不同的数据库对这套标准有不同的实现,这与流量器有自己对 Web 标准的实现类似,这让不同数据库之前的 SQL 不能通用。
PL/SQL 是 Oracle 数据库对 SQL 标准的实现,它对标准 SQL 进行了扩展,让其具有过程化编程语言的能力,在 PL/SQL 中,你可以轻松实现数组、循环、判断等操作。
MySQL 也对 SQL 标准有自己的实现,事实是,MySQL 实现的 SQL 相比于 PL/SQL 弱了很多,它更擅长与数据的操作,而不是过程化的程序编程。
我之所以选择 MySQL,有几点原因:
1. 目前没发现有人通过 MySQL 来解八皇后问题,没有参考答案。2.MySQL 的 SQL 语言对过程化支持比较弱,有点挑战。3.MySQL 是大部分程序员都使用的数据库,大家比较熟悉(方便理解我装的 B)。
因为没人弄过,我也不熟悉 MySQL 流程控制相关的语法,所以一开始我是没有把握的,但解决问题的过程才有意思。
为了描述方便,后文以 SQL 表示 MySQL 中的 SQL,以 MySQL 表示数据库。
此外,MySQL 不同版本间的 SQL 实现可能也有所差异,本文使用的 MySQL 版本为 8.0.19,大家可以自行通过 select version(); 查看自己 MySQL 的版本。
Python 解题
我的解题思路很简单,用一个长度为 8 的列表来存皇后位置,具体而言,列表的下标表示当前皇后所在的行,该下标对应的值则表示该行上皇后所在的列,这样不同的皇后所在的行就不会重复了,所以只需要判断列和斜边是否会冲突。
具体的 Python 代码如下:
num=0
defis_ok(queen,row):
forrinrange(1,row):
#第r行与第row行皇后在同一列,冲突
ifqueen[r]==queen[row]:
returnFalse
t=abs(queen[r]-queen[row])
#第r行与第row行皇后在同一斜线,冲突
#如果2个皇后所在位置的行差与列差相同,则在同一斜线
ift==abs(r-row):
returnFalse
returnTrue
deffind(queen,row):
globalnum
#每一行都从第一列到第八列进行尝试
forcolinrange(1,(8+1)):
queen[row]=col
#判断是否满足条件
ifis_ok(queen,row):
ifrow==8:
num+=1
return
#如果没有到第八行,则继续递归
find(queen,row+1)
#Python列表下标从0开始,为了从1开始,所以这样
queen=[0,1,2,3,4,5,6,7,8]
find(queen,1)
print('resultis',num)
去除注释,代码其实很短。
当然还有更优的解法,大家可以上力扣看看,我看了其 Python 版的代码,我感觉代码太多了…
Python 版的解法有了,后面要做的就是将他翻译成 SQL 的形式,这个过程有蛮多问题的。
没有数组怎么办?
在 MySQL 实现的 SQL 中,是不存在容器类型的变量的,即数组、字典这些在语言层面上不支持,怎么办呢?
通过 Google 搜索,发现大多数人的做法是利用字符串来模拟数组,字符串以逗号作为分割,然后通过字符相关的方法来实现字符串的中元素的查找与更新,具体可以看参考部分给出的文章。
经过试验,我发现这个方式并不好用,在我的 MySQL 上,运行会报语法错误。
简单思考后,我决定使用临时表的方式来解决数组的。
临时表主要用于临时保存一些数据,它的特点是只对创建该表的用户可见,当会话结束上,MySQL 会自动删除临时表,它的优势在于:建表和删表消耗资料都极小,其创建的语法为:
CREATETEMPORARYTABLEtbl_name(...);
即正常建表语句中加上 TEMPORARY 关键字则可,具体的语句如下。
--如果临时表存在,则删除临时表 DROPTABLEIFEXISTSqueen; --id模仿列表的下标,location存列表中的值 CREATETEMPORARYTABLEqueen(idINT,locationINT);
看回 Python 的代码,可以发现,默认设置了对应的值。
queen=[0,1,2,3,4,5,6,7,8]
为了模仿这种效果,临时表中也要有对应的默认值,因为 MySQL 中的表其下标是从 1 开始的,所以只需要创建 8 行则可,这里我定义了一个存储过程来实现初始化临时表中值的效果,代码如下:
--如果存储过程存在,则删除该PROCEDURE(过程) DROPPROCEDUREIFEXISTSinit_queen; --定义过程 CREATEPROCEDUREinit_queen() BEGIN --声明变量 DECLAREiintDEFAULT1; --循环 WHILEi<=8DO --将值插入表 INSERTINTOqueen(id,location)VALUES(i,-1); SETi=i+1; ENDWHILE; END;
从注释应该可以理解上述 SQL 的逻辑。
需要注意的是,MySQL 的存储过程并不是函数,所谓存储过程只是用户定义一系列 SQL 语句的集合,在遇到需要重复使用的 SQL 语句时,可以将其定义为存储过程,在执行过程中,MySQL 会对其进行相应的优化。
存储过程通过 PROCEDURE 关键字定义,可以接受多个参数,也可以返回多个参数,但没有 return 语句,其返回的值,通过复制给同名参数的形式实现,通过下面的代码应该可以理解我所表达的意思。
因为后续解八皇后算法时会涉及到列表元素的增删改查,所以我封装了多个存储过程来实现对临时表的增删改查。
DROPPROCEDUREIFEXISTSget_queen; --in_id为传入参数,out_lcation为传出参数 CREATEPROCEDUREget_queen(INin_idINT,OUTout_locationINT) BEGIN --通过id获得对应的location,并通过INTO关键字将获得的值赋值给out_location,实现查询结果的返回 SELECTlocationINTOout_locationFROMqueenWHEREid=in_id; END; --通过id更新对应的位置 DROPPROCEDUREIFEXISTSupdate_queen; --多个传入参数 CREATEPROCEDUREupdate_queen(INin_idINT,INnew_locationINT) BEGIN --更新值 UPDATEqueenSETlocation=new_locationWHEREid=in_id; END;
看到 get_queen 方法,其返回值的方式是将需返回的值赋值给 out_location 参数,使用示例如下:
--通过CALL关键字调用存储过程,通过@表示变量,@q1则是用于接受结果的变量 CALLget_queen(r,@q1);
遗憾的是,临时表在 MySQL 中的支持也是有限的,当你在具体使用时,会出现「Can’t reopen table 错误」。
这是 MySQL 特有的问题,即临时表不能重复使用,这个问题存在已久,但已经没有被解决,MariaDB(MySQL 另外一个分支)已经解决这个问题。
一个简单的解决方案是复制临时表。如果表相对较小,则可以很好地工作,临时表通常就是这种情况。
为了避免这个情况,我直接创建普通表,即会落盘到磁盘中,从而避免这个问题。
即将下面代码
DROPTABLEIFEXISTSqueen; CREATETEMPORARYTABLEqueen(idINT,locationINT);
修改为:
DROPTABLEIFEXISTSqueen; CREATETABLEqueen(idINT,locationINT);
相关的讨论可以看:参考 4
如何打印日志?
使用 Python 时,我们可以通过 print 方法打印一些内容来方便我们判断当前程序执行流程是否正常,那 SQL 中怎么搞?
目前,我在 Navicat 上编写并执行 SQL,经过查询,Navicat 似乎是无法进行 Debug 的,而 MySQL 也不知道打印,这就很蛋疼,毕竟写比较多的 SQL 时,没有日志比较难看出代码中的 Bug。
为了实现查看执行流程,我觉得单独创建一个表来记录日志,然后定义一个存储过程将相关的信息写入表中,从而实现查看执行日志的目的。
--创建日志表
DROPTABLEIFEXISTSqueen_log;
CREATETABLEqueen_log
(
idINTUNSIGNEDNOTNULLPRIMARYKEYAUTO_INCREMENT,
logVARCHAR(500)NOTNULL
);
--定义存储过程
DROPPROCEDUREIFEXISTSadd_log;
CREATEPROCEDUREadd_log(INin_logVARCHAR(500))
BEGIN
--将日志插入到表中
INSERTINTOqueen_log(log)VALUES(in_log);
END;
CALLadd_log('一条日志');
定义判断函数
在 Python 实现中,我们定义了 is_ok 方法来判断当前皇后的落子是否满足条件,这里通过 SQL 将这个方法再实现一遍。
在实现前,需要再次讨论一下存储过程与函数的差异。
在 SQL 中,存储过程必然会将其中的逻辑执行完,不会中途跳出,即没有 return 方法,而函数可以使用 return 方法在执行的过程中退出函数,但函数的局限在于函数只能返回单个结果,而存储过程可以获得多个返回结果。
回顾一下 is_ok 方法,该方法只需返回 True 或 False 单个结果用于表示当前皇后是否可以落子则可,在满足条件时,is_ok 方法直接通过 return 返回。
简单思考一下,可以发现 is_ok 方法更适合于使用 MySQL 的函数去实现。
--如果函数之前存在,则删除 DROPFUNCTIONIFEXISTSis_ok; --定义函数,函数名为is_ok,函数的输入为in_row CREATEFUNCTIONis_ok(in_rowINT) --函数是返回值,INT表示返回值的类型,DETERMINISTIC是语法上要求的写法 RETURNSINTDETERMINISTIC --函数的注释 COMMENT'判断当前落子位置是否满足条件' BEGIN --声明变量 DECLAREtintDEFAULT-1; DECLARErintDEFAULT1; WHILE(r<=(in_row-1))DO --queen表中存的是col CALLget_queen(r,@q1); CALLget_queen(in_row,@q2); --第r行与第in_row行在同一列上,冲突 IF(@q1=@q2)THEN --函数返回-1 RETURN-1; ENDIF; --列数相减 SETt=ABS(@q1-@q2); --第r行与第row行皇后在同一斜线,冲突 IF(t=ABS(r-in_row))THEN RETURN-2; ENDIF; --加一 SETr=r+1; ENDWHILE; RETURN1; END;
SQL 版 is_ok 函数的实现比较直观,因为我们通过表来实现队列,所以我们不需要将 queen 列表传入,表结构是全局可见的。
递归限制
掌握了 MySQL 流程控制(IF、WHILE 等)、存储过程、函数等用法后,我感觉自己很快就可以用 MySQL 解出八皇后问题了。
很快,我用函数写了 SQL 版的 find 函数,find 函数中使用了 is_ok 函数,然后再回调自身,代码如下:
DROPFUNCTIONIFEXISTSfind; CREATEFUNCTIONfind(in_rowINT) RETURNSINTDETERMINISTIC COMMENT'判断当前落子位置是否满足条件' BEGIN DECLAREcolintDEFAULT1; WHILEcol<=8DO CALLget_queen(in_row,@old_location); CALLupdate_queen(in_row,col); --满足条件 IF(is_ok(in_row)=1)THEN IF(in_row=8)THEN SET@num=@num+1; --满足条件跳出递归 RETURN0; ENDIF; --尚未查找到第8行,第归查找一下行 SET@a=find(in_row+1); ENDIF; --还原递归的值 CALLupdate_queen(in_row,@old_location); --下一次循环 SETcol=col+1; ENDWHILE; RETURN0; END;
但 MySQL 中,函数是不能回调的… 会出现「Recursive stored functions and triggers are not allowed 报错」。
此时就陷入了一个困境:
find 之所以用函数是想着满足条件后就直接 return 返回,结果发现函数不支持递归,只能存储过程才支持递归调用。
如果使用存储过程,它没有 return 关键字,在满足条件后,无法通过 return 返回,只能将所有逻辑执行完后,自动结束,这就需要改蛮多代码的。
最后我发现了 LEAVE 关键字,该关键字主要用于跳出 WHILE 循环,类似于 Python 中的 break 关键字,利用这个方法,在满足条件时,我直接跳出 find 方法的主循环,从而达到 return 返回的效果。
find 最终的代码如下:
SET@num:=0;
--设置递归查询的层深上限
SETmax_sp_recursion_depth=500;
--计算八皇后可能的结果
DROPPROCEDUREIFEXISTSfind;
CREATEPROCEDUREfind(INin_rowINT)
BEGIN
DECLAREcolINTDEFAULT1;
--添加日志
CALLadd_log('findprocedureisrunning.');
--循环处,有loop1标识
loop1:WHILEcol<=8DO
CALLget_queen(in_row,@old_location);
CALLupdate_queen(in_row,col);
--满足条件
SET@res=is_ok(in_row);
--添加日志
CALLadd_log(CONCAT('is_okrunning,in_row:',in_row,'col:',col,'res:',@res));
IF(@res=1)THEN
IF(in_row=8)THEN
SET@num=@num+1;
CALLadd_log(CONCAT('numis:',@num));
--满足条件跳出递归
LEAVEloop1;
ENDIF;
--未到第8行,继续递归
CALLfind(in_row+1);
--还原递归的值
CALLupdate_queen(in_row,@old_location);
ENDIF;
--下一次循环
SETcol=col+1;
--循环处,有loop1标识
ENDWHILEloop1;
END;
还需要注意的一点是,MySQL 对递归深度是有较严格限制的,所以我们需要设置一下 max_sp_recursion_depth。
--设置递归查询的层深上限 SETmax_sp_recursion_depth=500;
实现过程中遇到的问题与解决方案。
Not allowed to return a result set from a function 错误
该错误表明:不允许从函数返回结果集。
即你定义的函数中,不能使用 SELECT 打印数据,MySQL 会认为在方法中打印数据是要返回相关的结果集。
Recursive stored functions and triggers are not allowed 报错
MySQL 的方法不支持递归调用,但存储过程可以。
Recursive limit 0 报错
需要修改 max_sp_recursion_depth。
这个修改涉及到全局和 session 级修改, 全局修改的话 需要 有 super 权限:set global max_sp_recursion_depth=2, session 级修改的话只对当前连接有效,不需要加 global。
Thread stack overrun 错误
错误原因:
thread_stack 太小,默认 128K。
通过下面命令可以查看
mysql>showvariableslike'%thread%'; +-----------------------------------------+---------------------------+ |Variable_name|Value| +-----------------------------------------+---------------------------+ |create_admin_listener_thread|OFF| |innodb_parallel_read_threads|4| |thread_handling|one-thread-per-connection| |thread_stack|286720| +-----------------------------------------+---------------------------+ 18rowsinset(0.02sec) 删除的部分无关内容,减少展示
看到其中的 thread_stack 为 286720 Bytes 即 280KB。
最终结果
将上面的代码整理在一起,就获得了最终的 SQL 代码,完整代码如下:
DROPTABLEIFEXISTSqueen;
CREATETABLEqueen(idINT,locationINT);
DROPTABLEIFEXISTSqueen_log;
CREATETABLEqueen_log
(
idINTUNSIGNEDNOTNULLPRIMARYKEYAUTO_INCREMENT,
logVARCHAR(500)NOTNULL
);
DROPPROCEDUREIFEXISTSadd_log;
CREATEPROCEDUREadd_log(INin_logVARCHAR(500))
BEGIN
INSERTINTOqueen_log(log)VALUES(in_log);
END;
DROPPROCEDUREIFEXISTSinit_queen;
CREATEPROCEDUREinit_queen()
BEGIN
DECLAREiintDEFAULT1;
WHILEi<=8DO
INSERTINTOqueen(id,location)VALUES(i,i);
SETi=i+1;
ENDWHILE;
END;
DROPPROCEDUREIFEXISTSget_queen;
CREATEPROCEDUREget_queen(INin_idINT,OUTout_locationINT)
BEGIN
SELECTlocationINTOout_locationFROMqueenWHEREid=in_id;
END;
DROPPROCEDUREIFEXISTSupdate_queen;
CREATEPROCEDUREupdate_queen(INin_idINT,INnew_locationINT)
BEGIN
UPDATEqueenSETlocation=new_locationWHEREid=in_id;
END;
DROPFUNCTIONIFEXISTSis_ok;
CREATEFUNCTIONis_ok(in_rowINT)
RETURNSINTDETERMINISTIC
COMMENT'判断当前落子位置是否满足条件'
BEGIN
DECLAREtintDEFAULT-1;
DECLARErintDEFAULT1;
WHILE(r<=(in_row-1))DO
CALLget_queen(r,@q1);
CALLget_queen(in_row,@q2);
IF(@q1=@q2)THEN
RETURN-1;
ENDIF;
SETt=ABS(@q1-@q2);
IF(t=ABS(r-in_row))THEN
RETURN-2;
ENDIF;
SETr=r+1;
ENDWHILE;
RETURN1;
END;
SET@num:=0;
SETmax_sp_recursion_depth=500;
--计算八皇后可能的结果
DROPPROCEDUREIFEXISTSfind;
CREATEPROCEDUREfind(INin_rowINT)
BEGIN
DECLAREcolINTDEFAULT1;
CALLadd_log('findprocedureisrunning.');
loop1:WHILEcol<=8DO
CALLget_queen(in_row,@old_location);
CALLupdate_queen(in_row,col);
SET@res=is_ok(in_row);
CALLadd_log(CONCAT('is_okrunning,in_row:',in_row,'col:',col,'res:',@res));
IF(@res=1)THEN
IF(in_row=8)THEN
SET@num=@num+1;
CALLadd_log(CONCAT('numis:',@num));
LEAVEloop1;
ENDIF;
CALLfind(in_row+1);
CALLupdate_queen(in_row,@old_location);
ENDIF;
SETcol=col+1;
ENDWHILEloop1;
END;
CALLinit_queen();
CALLfind(1);
SELECT@num;
如果比较难理解,可以看回文中讲解代码时的注释。
最终效果如下:
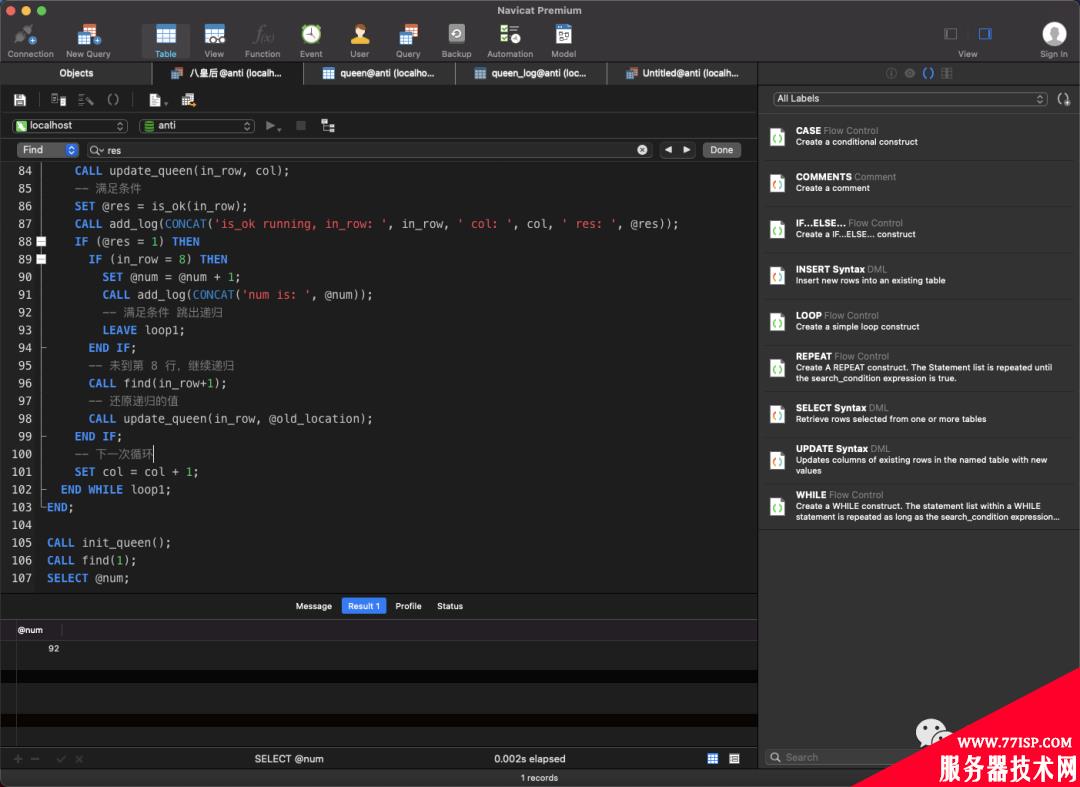
执行日志:
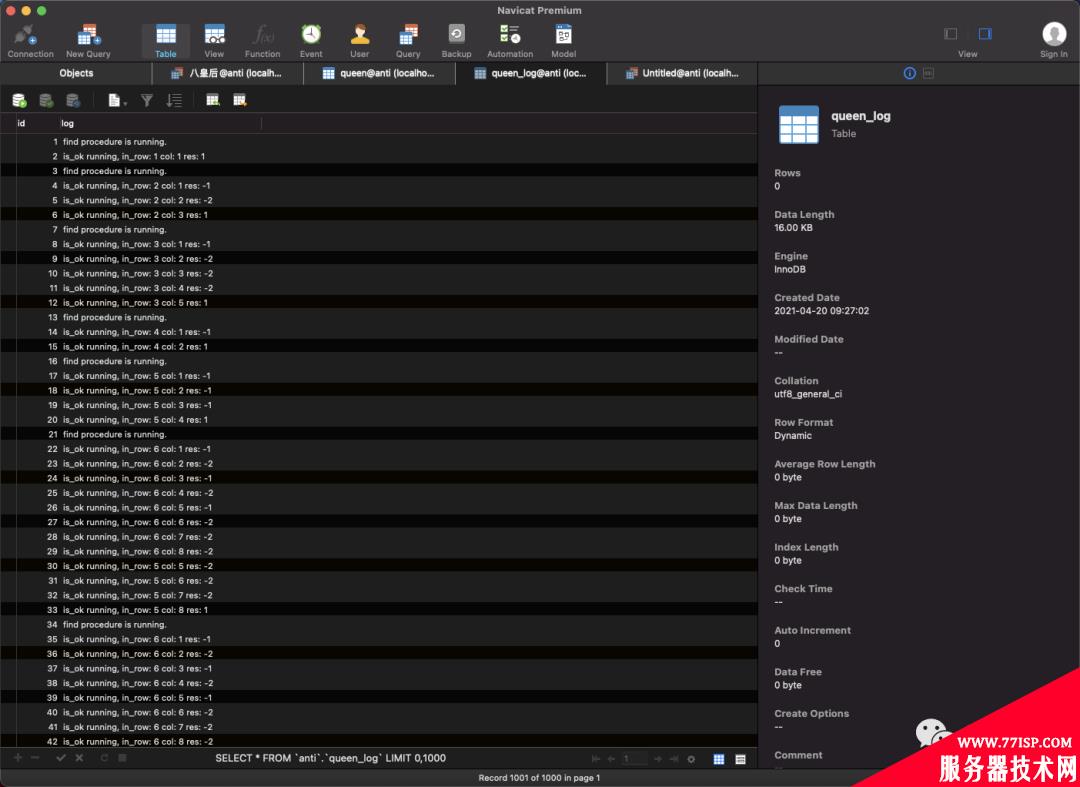
查询计算过程:

对了,这个程序大概运行了 2.9 分钟,非常的慢,可能是递归过程中涉及了大量 INSERT 操作。
从运行速度也可以判断出,这个程序没啥用,是的,没啥用,但我折腾的比较开心,这就够了??。
广告算法的内容已经安排上了,记得来看呀,那我们下篇文章见。
原文链接:https://77isp.com/post/10364.html
=========================================
https://77isp.com/ 为 “云服务器技术网” 唯一官方服务平台,请勿相信其他任何渠道。
数据库技术 2022-03-28
网站技术 2022-11-26
网站技术 2023-01-07
网站技术 2022-11-17
Windows相关 2022-02-23
网站技术 2023-01-14
Windows相关 2022-02-16
Windows相关 2022-02-16
Linux相关 2022-02-27
数据库技术 2022-02-20
抠敌 2023年10月23日
嚼餐 2023年10月23日
男忌 2023年10月22日
瓮仆 2023年10月22日
簿偌 2023年10月22日
扫码二维码
获取最新动态
