
2022-10-27 371
线上某IOT核心业务集群之前采用MySQL作为主存储数据库,随着业务规模的不断增加,MySQL已无法满足海量数据存储需求,业务面临着容量痛点、成本痛点问题、数据不均衡问题等。
400亿该业务迁移MongoDB后,同样的数据节省了极大的内存、CPU、磁盘成本,同时完美解决了容量痛点、数据不均衡痛点,并且实现了一定的性能提升。
此外,迁移时候的MySQL数据为400亿,3个月后的现在对应MongoDB集群数据已增长到1000亿,如果以1000亿数据规模等比例计算成本,实际成本节省比例会更高。迁移MongoDB后,除了解决业务痛点问题,同时也促进了业务的快速迭代开发,业务不在关心数据库容量痛点、数据不均衡痛点、成本痛点等问题。
当前国内很多mongod文档资料、性能数据等还停留在早期的MMAP_V1存储引擎,实际上从MongoDB-3.x版本开始,MongoDB默认存储引擎已经采用高性能、高压缩比、更小锁粒度的wiredtiger存储引擎,因此其性能、成本等优势相比之前的MMAP_V1存储引擎更加明显。
该业务在迁移MongoDB前已有约400亿数据,申请了64套MySQL集群,由业务通过shardingjdbc做分库分表,提前拆分为64个库,每个库100张表。主从高可用选举通过依赖开源orchestrator组建,MySQL架构图如下图所示:
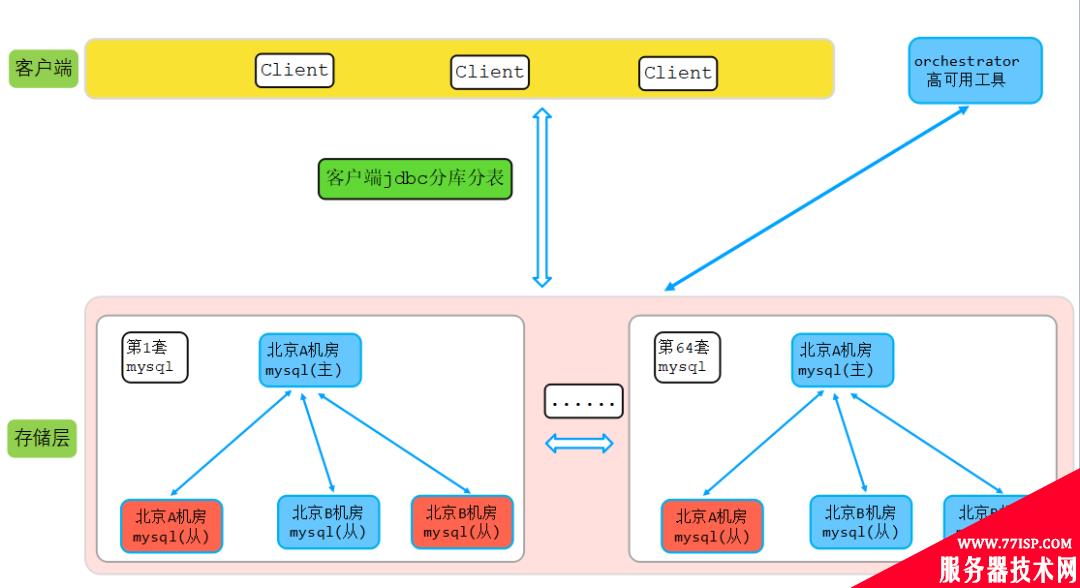
说明:上图中红色代表磁盘告警,磁盘使用水位即将100%。如上图所示,业务一年多前一次性申请了64套MySQL集群,单个集群节点数一主三从,每个节点规格如下:
该业务运行一年多时间后,总集群数据量达到了400亿,并以每月200亿速度增长,由于数据不均衡等原因,造成部分集群数据量大,持续性耗光磁盘问题。由于节点众多,越来越多的集群节点磁盘突破瓶颈,为了解决磁盘瓶颈,DBA不停的提升节点磁盘容量。业务和DBA都面临严重痛点,主要如下:
DBA工作量剧增(部分磁盘提升不了需要迁移数据到新节点),业务也提心吊胆
业务遇到瓶颈后,基于MongoDB在公司已有的影响力,业务开始调研MongoDB,通过和业务接触了解到,业务使用场景都是普通的增、删、改、查、排序等操作,同时查询条件都比较固定,用MongoDB完全没任何问题。
此外,MongoDB相比传统开源数据库拥有如下核心优索:
MongoDB为schema-free结构,数据格式没有严格限制。业务数据结构比较固定,该功能业务不用,但是并不影响业务使用MongoDB存储结构化的数据。
MySQL高可用依赖第三方组件来实现高可用,MongoDB副本集内部多副本通过raft协议天然支持高可用,相比MySQL减少了对第三方组件的依赖。
MongoDB是分布式数据库,完美解决MySQL分库分表及海量数据存储痛点,业务无需在使用数据库前评估需要提前拆多少个库多少个表,MongoDB对业务来说就是一个无限大的表(当前我司最大的表存储数千亿数据,查询性能无任何影响)。
此外,业务在早期的时候一般数据都比较少,可以只申请一个分片MongoDB集群。而如果采用MySQL,就和本次迁移的IOT业务一样,需要提前申请最大容量的集群,早期数据量少的时候严重浪费资源。
MongoDB在设计上根据不同一致性等级需求,支持不同类型的Read Concern 、Write Concern读写相关配置,客户端可以根据实际情况设置。此外,MongoDB内核设计拥有完善的rollback机制来保证数据安全性和一致性。
为了适应大规模高并发业务读写,MongoDB在线程模型设计、并发控制、高性能存储引擎等方面做了很多细致化优化。
网上很多评论还停留在早期MMAPv1存储引擎,相比MMAPv1,wiredtiger引擎性能更好,压缩比更高,锁粒度更小,具体如下:
zlib压缩算法压缩比约为4.5-7.5倍(本次迁移采用zlib高压缩算法)
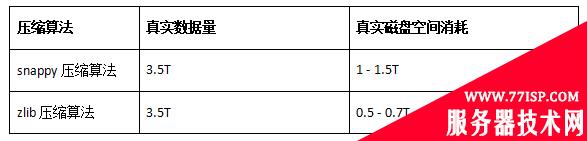
此外,以线上已有的从MySQL、Es迁移到MongoDB的真实业务磁盘消耗统计对比,同样的数据,存储在MongoDB、MySQL、Es的磁盘占比≈1:3.5:6。
后续会有数千亿hbase数据迁移MongoDB,到时候总结同样数据MongoDB和Hbase的磁盘消耗比。
MongoDB天然高可用机制及代理标签自动识别转发功能的支持,可以通过节点不同机房部署来满足同城和异地N机房多活容灾需求,从而实现成本、性能、一致性的“三丰收”。更多机房多活容灾的案例详见Qcon分享:
MongoDB客户端访问路由策略由客户端自己指定,该功能通过Read Preference实现,支持primary 、primaryPreferred 、secondary 、secondaryPreferred 、nearest 五种客户端均衡访问策略。
分布式事务支持
MongoDB-4.2 版本开始已经支持分布式事务功能,当前对外文档版本已经迭代到 version-4.2.11,分布式事务功能也进一步增强。此外,从 MongoDB-4.4 版本产品规划路线图可以看出,MongoDB 官方将会持续投入开发查询能力和易用性增强功能,例如 union 多表联合查询、索引隐藏等。
业务开始迁移MongoDB的时候,通过和业务对接梳理,该集群规模及业务需求总结如下:
说明:数据规模和磁盘消耗按照单副本计算,例如MySQL 64个分片,256个副本,数据规模和磁盘消耗计算方式为:64个主节点数据量之和、64个分片主节点磁盘消耗之和。
分片数及存储节点套餐规格选定评估过程如下:
内存评估
我司都是容器化部署,以往经验来看,MongoDB对内存消耗不高,历史百亿级以上MongoDB集群单个容器最大内存基本上都是64Gb,因此内存规格确定为64G。
分片评估
业务流量峰值3-5W/s,考虑到可能后期有更大峰值流量,因此按照峰值10W/s写,5w/s读,也就是峰值15W/s评估,预计需要4个分片。
磁盘评估
MySQL中已有数据400亿,磁盘消耗30T。按照以网线上迁移经验,MongoDB默认配置磁盘消耗约为mysql的1/3-1/5,400亿数据对应MongoDB磁盘消耗预计8T。考虑到1500亿数据,预计4个分片,按照每个分片400亿规模,预计每个分片磁盘消耗8T。
线上单台物理机10多T磁盘,几百G内存,几十个CPU,为了最大化利用服务器资源,我们需要预留一部分磁盘给其他容器使用。另外,因为容器组套餐化限制,最终确定确定单个节点磁盘在7T。预计7T节点,4个分片存储约1500亿数据。
CPU规格评估
由于容器调度套餐化限制,因此CPU只能限定为16CPU(实际上用不了这么多CPU)。
mongos代理及config server规格评估
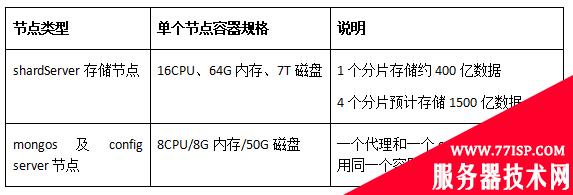
此外,由于分片集群还有mongos代理和config server复制集,因此还需要评估mongos代理和config server节点规格。由于config server只主要存储路由相关元数据,因此对磁盘、CUP、MEM消耗都很低;mongos代理只做路由转发只消耗CPU,因此对内存和磁盘消耗都不高。最终,为了最大化节省成本,我们决定让一个代理和一个config server复用同一个容器,容器规格如下:
由于该业务所在城市只有两个机房,因此我们采用2+2+1(2mongod+2mongod+1arbiter模式),在A机房部署2个mongod节点,B机房部署2个mongod节点,C机房部署一个最低规格的选举节点,如下图所示:
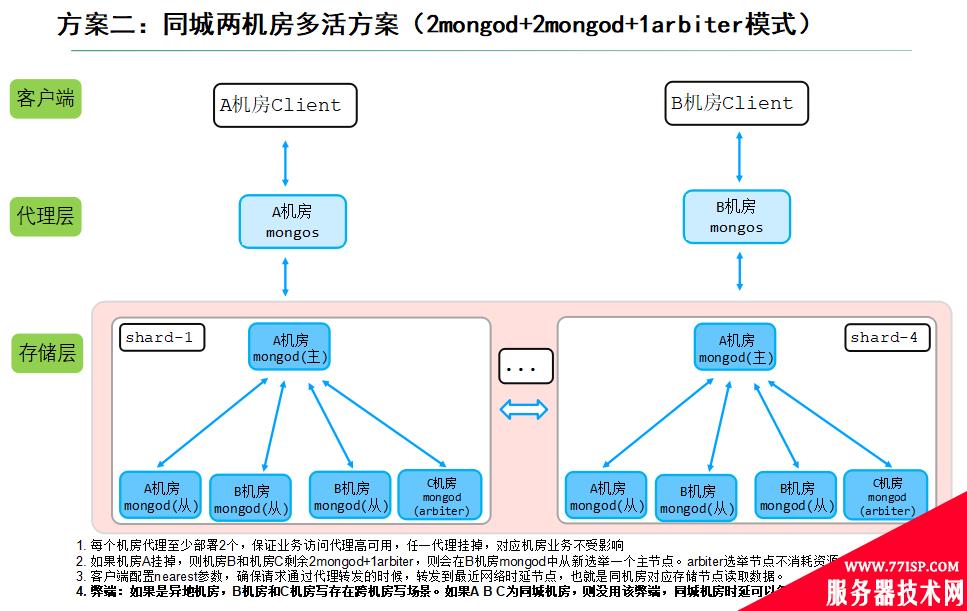
说明:
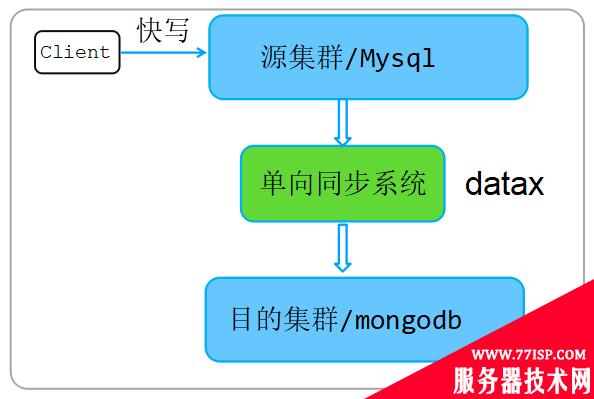
迁移过程由业务自己完成,通过阿里开源的datax工具实现,该迁移工具的更多细节可以
原文链接:https://77isp.com/post/10398.html
=========================================
https://77isp.com/ 为 “云服务器技术网” 唯一官方服务平台,请勿相信其他任何渠道。
数据库技术 2022-03-28
网站技术 2022-11-26
网站技术 2023-01-07
网站技术 2022-11-17
Windows相关 2022-02-23
网站技术 2023-01-14
Windows相关 2022-02-16
Windows相关 2022-02-16
Linux相关 2022-02-27
数据库技术 2022-02-20
抠敌 2023年10月23日
嚼餐 2023年10月23日
男忌 2023年10月22日
瓮仆 2023年10月22日
簿偌 2023年10月22日
扫码二维码
获取最新动态
