
2022-10-27 348

有人说单表超千万数据就应该分库分表了,这么玩不合理啊。但是对于创新业务来讲,业务系统的设计不可能一上来就预估这么大的容量,成本和工期都不足矣完成系统的开发工作。我觉得对于创新型业务系统的设计,首先满足需求,其次考虑到万一业务井喷发展所要考虑到的临时解决方案,为系统升级预留时间。
谁都希望业务井喷,那么它来了!
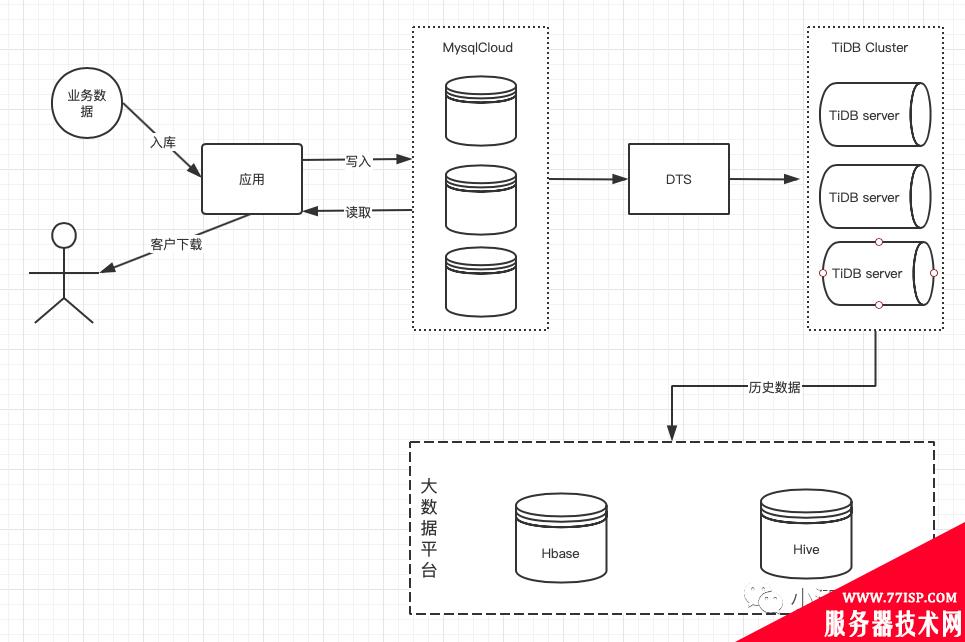
具体时间点就不说了,开始做了一个新业务,见了一个表,该表累计数据条不超过100万,提供查询功能。后来业务量持续上涨,mysql 磁盘开始报警,查询超时报警。而且,客户需要实时查询该业务表的数据并下载。头大,临时改存储方案已经来不及了,不能耽误KPI。
先解决眼下问题,先扩充磁盘。停止双机房同步,减少不必要的报警。
但是1000G 估计也扛不了多久,和业务同学讨论后,业务接受的范围T-7范围内的数据实时查询下载。按这个增长量,7天也是过亿的记录条数。但是7天的数据磁盘肯定是够用的,那就要先把历史数据离线存储。
这个也简单,几行代码的事儿。当然这样依靠完善的基建。
容量的问题解决了,那么改对数据分页查询的进行优化。为了说明问题,去掉敏感的业务数据,数据表结构如下:
CREATETABLE`t`( `id`bigint(20)unsignedNOTNULLAUTO_INCREMENTCOMMENT'主键', `a`char(32)DEFAULT''COMMENT'', `b`varchar(64)DEFAULTNULLCOMMENT'', `c`bigint(20)unsignedNOTNULLCOMMENT'', `d`varchar(64)NOTNULLCOMMENT'', `e`tinyint(4)DEFAULTNULLCOMMENT'', `f`int(11)NOTNULLDEFAULT'0'COMMENT'', `g`varchar(32)NOTNULLCOMMENT'', `h`char(32)DEFAULTNULLCOMMENT'', `i`varchar(64)DEFAULTNULLCOMMENT'', `j`varchar(64)DEFAULTNULLCOMMENT'', `k`datetimeDEFAULTNULLCOMMENT'', `l`int(11)DEFAULTNULLCOMMENT'', `m`timestampNULLDEFAULTNULLCOMMENT'', `n`timestampNULLDEFAULTNULLCOMMENT'' PRIMARYKEY(`id`), UNIQUEKEY`UK_b`(`b`), KEY`IDX_c`(`c`,)USINGBTREE )
当数据量少时,我们用下面的分页是没有问题的:
SELECTid,a,b…FROMtLIMITn,m
例如:
pagesize :每页显示条数。
pageno:页码
那么 m=pagesize; n=(pageno-1)*pagesize.
MySQL的limit工作原理就是先读取前面n条记录,然后抛弃前n条,读后面m条想要的,所以n越大,偏移量越大,性能就越差。
修改sql,减少io的消耗
SELECTid,a,b…FROMtwhereidin(SELECTidFROMtLIMITn,m)
其实这样也避免不了扫描前n 条,但是时间已经节约了很多。
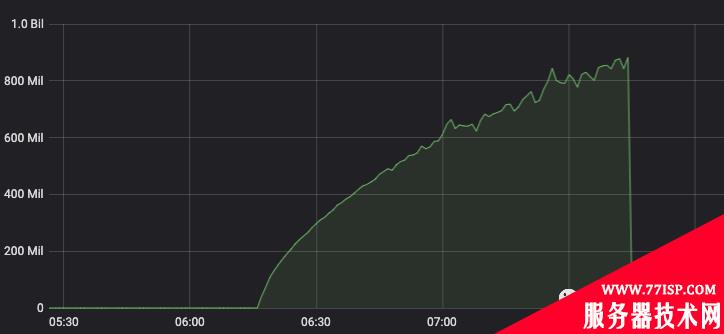
上面是每页请求的RT,可见随着页数的增加,RT 逐渐上升。

Qps 逐渐下降。
那么如果数据太多的话,最后一页超时的概率会非常大。
先卖个关子,先看看优化后的表现,这个接口的性能明显提升。如图所示:
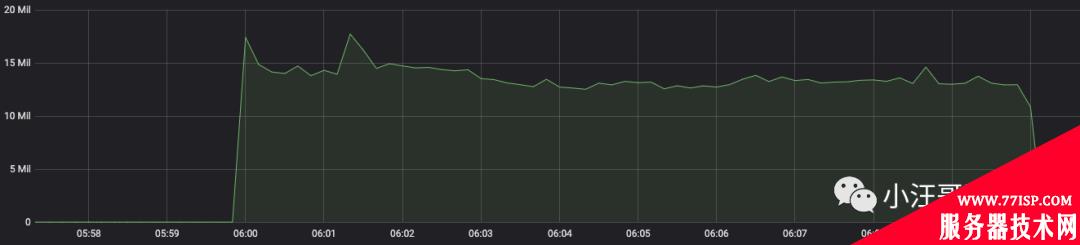
RT 平均在10ms 左右,因为返回做了数据处理,RT最终在15ms左右

qps 也很平稳,应该可以再高一些,取决于客户的调用。
全表扫描肯定不现实,这时我想到了LSM, Log Structured Merge Trees.这种数据结构,被用在许多产品的文件结构策略:HBase, Cassandra, LevelDB, SQLite,Kafka 等。是一种非常复杂的复合数据结构,它包含了 WAL(Write Ahead Log)、跳表(SkipList)和一个分层的有序表(SSTable,Sorted String Table)。
这里,没有必要实现一个LSM 树,只是参考了其稀疏索引的思想,能够准确定位数据。这样就简单了。步骤如下:
1.根据分析业务,构建一个 字段 a,b的联合索引。因为a,b 是数据的查询条件,且能分离出1/7的数据。
ALTERtableADDINDEXindex_a_b('a','b')
2.因为这个表的数据 都是通过 insert … on duplicate key update … 来更新的,【这也是线上死锁分析的那篇文章留下的伏笔】,而且 id 是自增主键,所以,所有的数据都是按照入库时的顺序来的,且后面遇到冲突时修改也是update 的,所以主键id 是不会变的。
在redis 中设计 稀疏索引。
在redis中设计稀疏索引。 key=a+b+页面 value=这页的起始id 比如以每页2条数据为例 key1=ab1value=0; key2=ab1value=4; key3=ab1value=8; ..... 那么第一页: select*fromtwhereid>0anda='a'b='b'limit2; 第二页: select*fromtwhereid>4anda='a'b='b'limit2; 第三页: select*fromtwhereid>8anda='a'b='b'limit2; ....
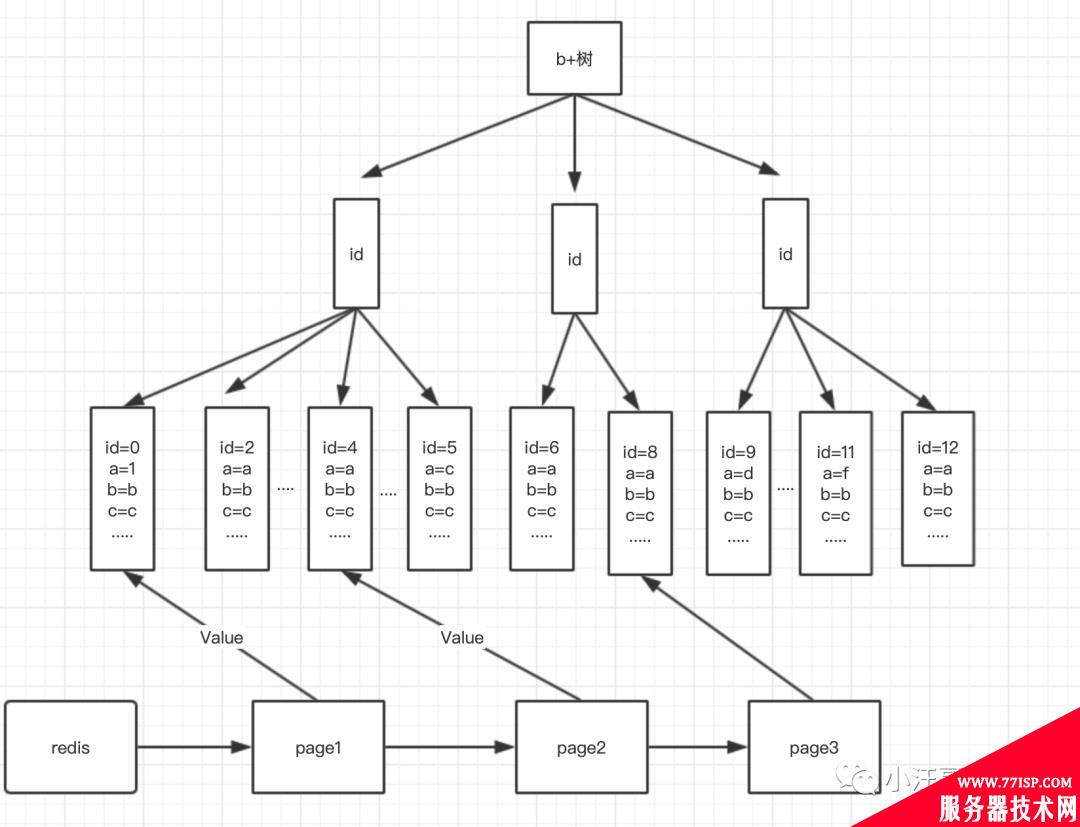
那么这样就能很快定位到每页的起始id,少了大量的扫描操作,同时使用了索引,虽然 ab 联合索引 在ab 值都是一样的时候 区分度不高,但是这样也保证了id的顺序,不用order by。因为主键索引的id 本来就是有序的。
在一批数据入库完成后开始稀疏索引的计算。
计算方法:
第一页 :id = 0
第一页数据 select*fromtwhereid>0anda='a'b='b'limit2;
第二页:id计算方法;
selectmax(t.id)from(select*fromtwhereid>0anda='a'b='b'limit2)t;
第三页:id计算方法;
selectmax(t.id)from(select*fromtwhereid>【第二页id】anda='a'b='b'limit2)t;
……….
依次类推…..
然后写入redis ,更新也是同样的道理。
有人肯定会说为什么不用覆盖索引呢,这样就不用回表了啊!
答案是不能;
假如我们返回的 字段 是 a,b ,c d,e,f,那么我们建一个 覆盖索引 x。x的B+树如下:
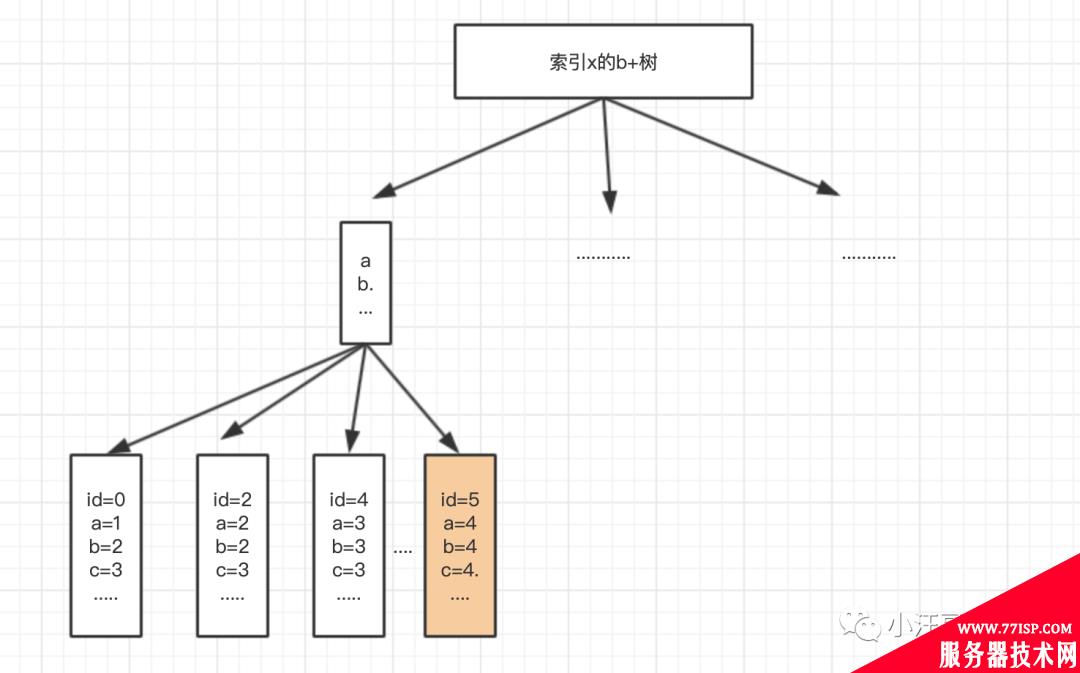
那如果这个时候 我改了id=5 的值a=4 改为a =1
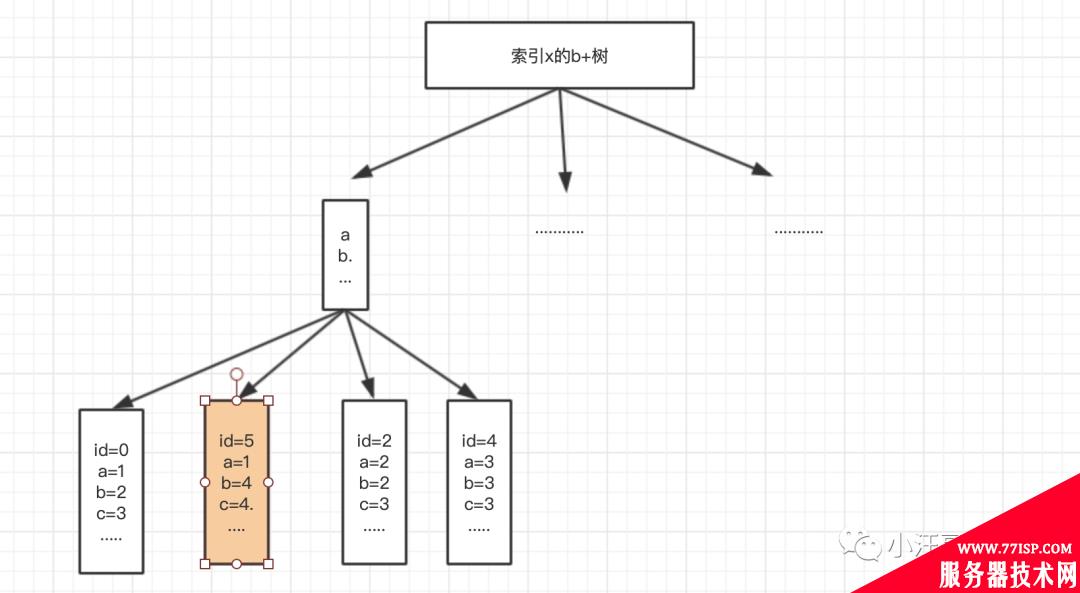
那现在id 就是不是顺序的了!!!!!!
数据量不大的话也是可以的,但是这又是何必呢。我们看看order by 的原理。
首先 MySQL 会为每个查询线程分配一块内存,叫做 sort_buffer,这块内存的作用就是用来排序的。这块内存有多大呢?由参数 **sort_buffer_size** 控制,可以通过如下命令来查看。
#查看sort_buffer的大小 showvariableslike'sort_buffer_size';
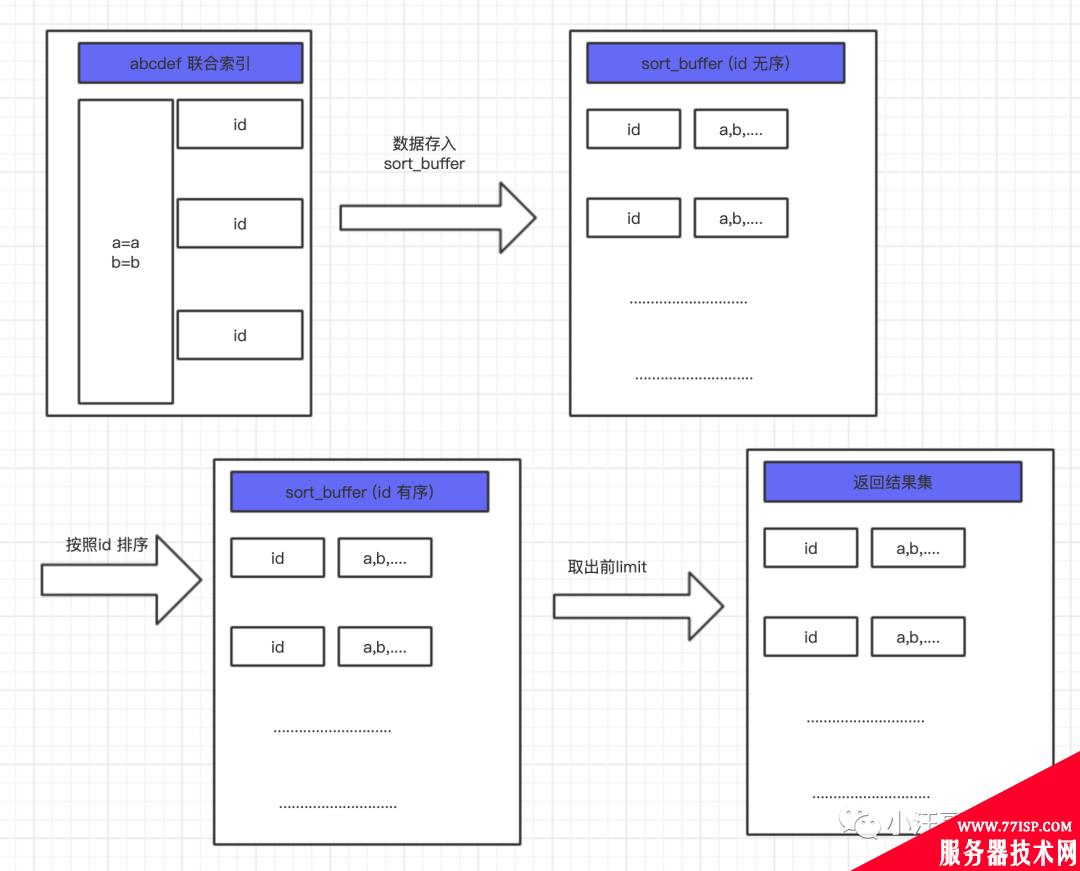
这样有两个问题:
每次都是按照筛选条件全量排序
如果数据量太大内存不够会触发文件排序,比较慢。
所以还是老老实实用了刚刚的方案。效果也还不错,也是仅仅加了几行代码而已
这个临时方案也是平稳运行了1年多。(>‿◠)
原文链接:https://77isp.com/post/10443.html
=========================================
https://77isp.com/ 为 “云服务器技术网” 唯一官方服务平台,请勿相信其他任何渠道。
数据库技术 2022-03-28
网站技术 2022-11-26
网站技术 2023-01-07
网站技术 2022-11-17
Windows相关 2022-02-23
网站技术 2023-01-14
Windows相关 2022-02-16
Windows相关 2022-02-16
Linux相关 2022-02-27
数据库技术 2022-02-20
抠敌 2023年10月23日
嚼餐 2023年10月23日
男忌 2023年10月22日
瓮仆 2023年10月22日
簿偌 2023年10月22日
扫码二维码
获取最新动态
